
- arquitectura web seo: guía práctica y lista de verificación - febrero 27, 2026
- Alt text SEO: guía práctica, checklist y automatizaciones - febrero 27, 2026
- Qué es el enlazado interno Interlinking y como afecta al SEO - septiembre 11, 2025
Si alguna vez has detectado URLs infinitas o repetitivas en tu web, mensajes de soft 404 en Google Search Console o un aumento extraño de páginas rastreadas pero no indexadas, es posible que estés frente a un crawl trap. Este problema, también conocido como crawl spider trap web, puede desperdiciar gran parte de tu crawl budget, retrasar la indexación de contenido importante y afectar la calidad percibida de tu sitio. En este artículo te explicamos qué es, por qué sucede, cómo detectarlo y las soluciones más efectivas para evitar que tu web caiga en esta trampa.
Qué es el web crawling y cómo funciona
El web crawling es el proceso mediante el cual bots (como Googlebot) descubren, rastrean y registran URLs para evaluarlas e incluirlas en el índice de un buscador. Estos bots siguen enlaces internos y externos, respetan normas como robots.txt y analizan el HTML de cada página para comprender su contenido y relaciones.
En herramientas SEO de escritorio y nube (por ejemplo, Screaming Frog o rastreadores propios) el mecanismo es similar: se parte de una o varias URLs semilla, se establece una cola de rastreo y se visitan páginas en función de reglas (profundidad, prioridad, estado HTTP, etc.). El objetivo es detectar issues técnicos, mapear la arquitectura y encontrar patrones problemáticos como un crawl trap o crawl spider trap web (p. ej., filtros infinitos, parámetros de sesión o calendarios sin límite).
- Descubrimiento: el bot recoge URLs desde el sitemap, enlaces internos y referencias externas.
- Rastreo: solicita cada URL, procesa respuestas (200, 3xx, 4xx, 5xx) y extrae nuevos enlaces.
- Procesamiento: evalúa contenido, metadatos, canónicas, directivas y señales de calidad.
- Priorización: decide qué y cuándo rastrear de nuevo según autoridad, cambios y rendimiento.
Cuando la arquitectura está bien diseñada, el rastreo fluye hacia las páginas clave. Si hay errores (bucles de enlaces, parámetros que combinan infinitas variantes, redirecciones mal planteadas), el bot malgasta recursos en URLs de poco valor y puede no llegar a tiempo a las secciones estratégicas.
Qué es el crawl budget y cómo afecta al rastreo web
El crawl budget es la combinación de capacidad de rastreo (lo que el bot está dispuesto a solicitar en tu sitio) y demanda de rastreo (lo que considera prioritario según señales como popularidad o cambios recientes). No es “número de páginas”, sino número de solicitudes que un bot realizará en un periodo.
Cómo afecta al rastreo web en crawl budget: un crawl trap desvía el presupuesto hacia URLs irrelevantes o infinitas (p. ej., combinaciones de filtros o parámetros de sesión). Esto provoca que el bot:
- Descubra tarde nuevas páginas importantes o actualizaciones críticas.
- Rastree con menor frecuencia secciones valiosas al “quemar” solicitudes en bucles.
- Interprete señales de baja calidad (duplicados, thin content), afectando la visibilidad.
En la práctica, cada solicitud “perdida” en un trap es una solicitud que no se invierte en contenido que sí debería recibir atención.
La relación es directa: a más desperdicio de crawl budget por traps, peor cobertura y frescura del índice. Por eso la prevención (arquitectura clara, control de parámetros, enlazado interno limpio) y la detección temprana con logs, Search Console y crawlers son esenciales.
Qué es un crawl trap y por qué sucede
Un crawl trap (también llamado crawl spider trap web) es una situación en la que un bot de rastreo entra en un bucle o en una proliferación prácticamente infinita de URLs de poco o nulo valor. El resultado es que el rastreador “se queda atrapado” y desperdicia solicitudes en variantes irrelevantes en lugar de llegar a las páginas importantes.
Origen técnico: suele deberse a fallos de arquitectura de la información o de implementación (parámetros sin control, paginaciones/filtrados combinables sin límite, enlaces relativos mal construidos, calendarios sin tope temporal, redirecciones erróneas, sesiones en la URL, etc.).
Problemas que causa:
- Desperdicio de crawl budget y retrasos en el descubrimiento de cambios relevantes.
- Señales de baja calidad (contenido duplicado, thin content, soft 404), que afectan a la visibilidad.
- Costes de servidor innecesarios por solicitudes repetitivas.
- Dificultad en auditorías (ruido y métricas sesgadas en crawls y logs).
Cómo identificar si tienes un crawl trap
Señales en Google Search Console
- Aumento anómalo de “Páginas rastreadas pero no indexadas” con patrones de parámetros.
- Errores de rastreo recurrentes (redirecciones múltiples, soft 404, bucles).
- Exploración por día inestable (picos sin cambios editoriales que lo justifiquen).
- Informe de Estadísticas de rastreo: rutas o parámetros que concentran la mayoría de solicitudes.
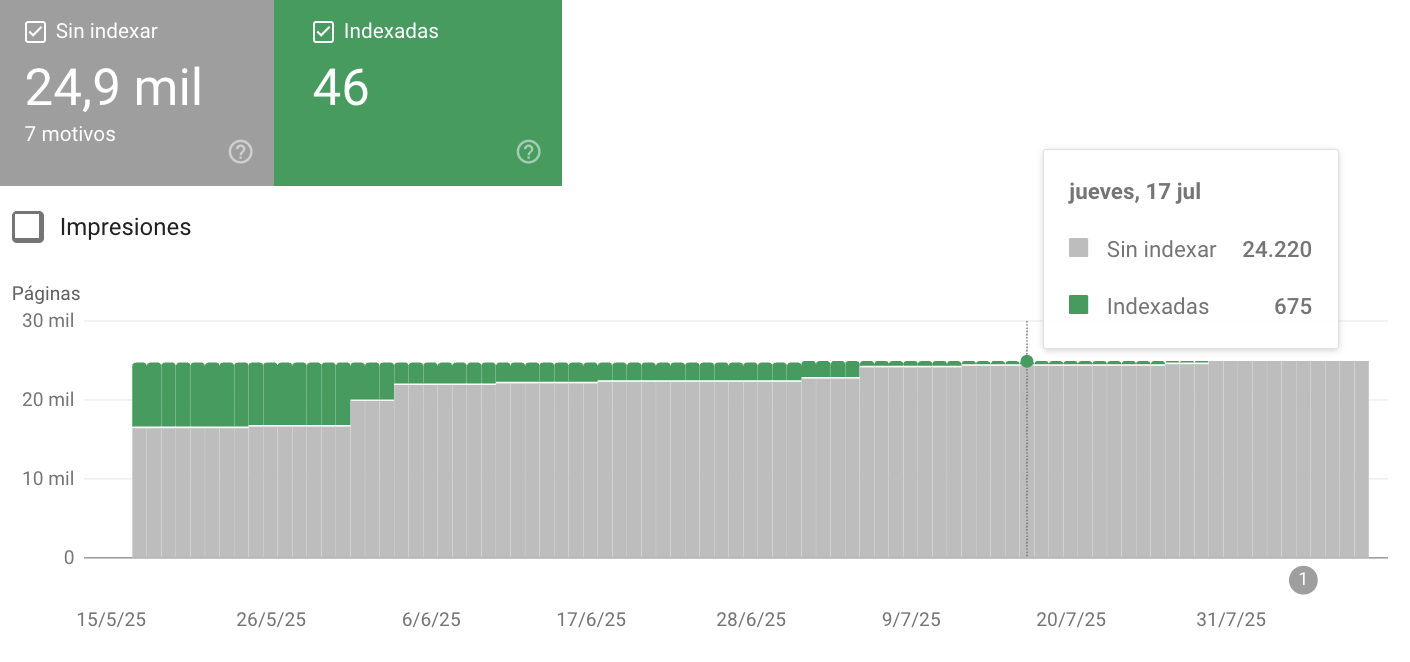
El número de páginas rastreadas aumenta de forma exponencial
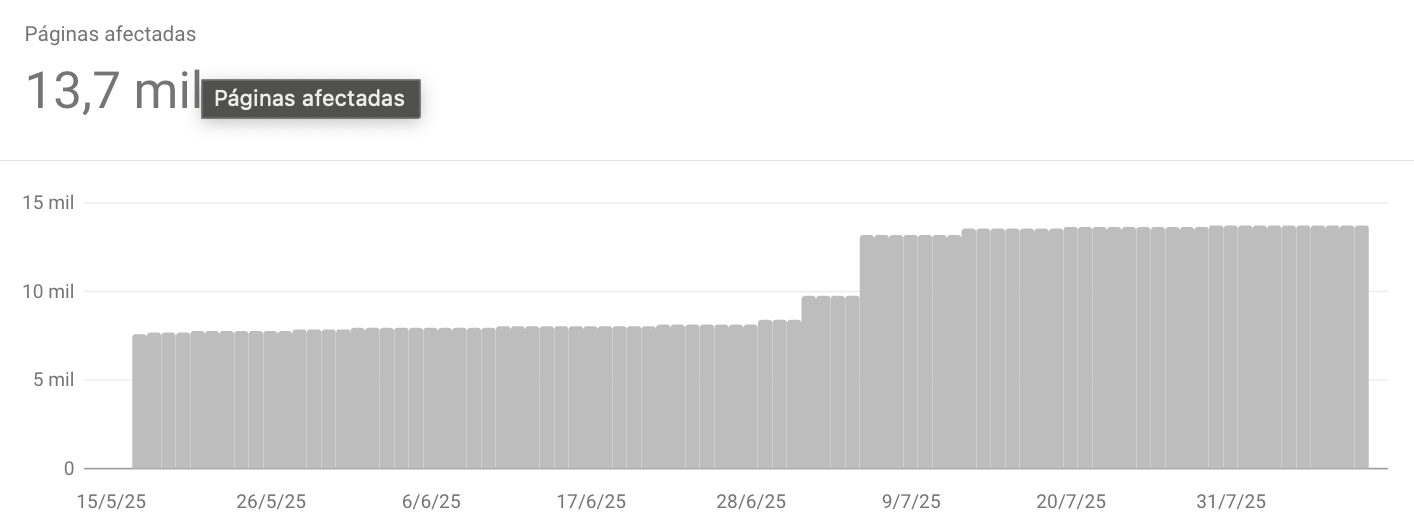
Se reciben alertas en Google Search Console indicando anomalías en el rastreo
Análisis con Screaming Frog y herramientas similares
- Profundidad desmesurada de clics hacia secciones que no deberían crecer tanto.
- Explosión de URLs con patrones repetidos (p. ej.,
?size=,?color=,?session=, fechas futuras). - Bucles de redirección (3xx encadenados) y enlaces relativos mal resueltos.
- Escaso contenido único (títulos/descripciones duplicados, canónicas incoherentes).
- Uso de Custom Extraction o filtros por regex para aislar parámetros problemáticos.
Revisión de logs del servidor
- Patrones repetitivos en peticiones de bots hacia rutas con parámetros combinables.
- Solicitudes a futuro en calendarios (
/calendar/AAAA/MMmuy lejanos). - HTTP 301/302 en bucle o cadenas largas de redirecciones.
- Altas tasas de 404/soft 404 en rutas generadas por errores de enlace.
Ejemplos frecuentes de crawl spider trap web
Redirecciones HTTPS / subdominio mal configuradas
Antiguas URLs HTTP o sin “www” que redirigen a la home en lugar de a su equivalente exacto en HTTPS/WWW. Genera soft 404 y reintentos del bot.
Filtro de productos (filter trap)
Combinaciones ilimitadas de filtros y ordenaciones (?size=, ?color=, ?sort=) que crean cientos o miles de variantes duplicadas sin control.
URLs infinitas (never-ending URL trap)
Enlaces relativos mal construidos (falta “/” inicial) que encadenan rutas del tipo /page1/page1/page1 generando niveles interminables.
Calendarios sin límite de fechas (time trap)
Plugins que permiten navegar meses/años indefinidamente hacia el futuro (o pasado), creando un número virtualmente infinito de páginas vacías.
Bucles de redirección (infinite redirect trap)
URLs que redirigen a sí mismas o entre sí en círculo. Google suele detectarlo, pero consume crawl budget y denota baja calidad interna.
Sesiones en URL (session URL trap)
Cuando la sesión no se guarda en cookies y se añade un ?session=ID a los enlaces. Cada visita del bot crea nuevas variantes de URL con el ID diferente, explotando el número de URLs.
Infección del sitemap por hackeo
Cuando un sitio web es comprometido, uno de los ataques más comunes es la inyección de URLs maliciosas directamente en el sitemap. Esto provoca que los buscadores rastreen e indexen páginas falsas o con spam, muchas veces bajo rutas que imitan secciones legítimas (/productos/, /blog/) pero que apuntan a contenido ajeno. Cada vez que el bot procesa el sitemap, añade estas URLs a su cola de rastreo, explotando el número de páginas rastreadas y desviando el crawl budget de las secciones reales.
¿Cómo solucionar un crawl trap?
La solución depende del tipo de trampa y de cómo se generan las URLs. El objetivo es doble: eliminar la causa (arquitectura/implementación) y reducir la exposición (control de rastreo y consolidación de señales).
Correcciones técnicas según el tipo de trampa
- HTTPS / subdominio mal configurado: unifica protocolo y host. Redirige 1:1 preservando la
request_uri(evita enviar todo a la home). Verifica quehttp → httpsynon-www ↔ wwwsean consistentes y sin bucles. - Filter trap (facetas/ordenaciones): limita combinaciones indexables, convierte filtros “no SEO” en interacciones que no generan enlaces navegables (
<button>o AJAX sin ancla), y canónicaliza al listado base. Evita enlazar internamente a combinaciones infinitas. - Never‑ending URL trap: corrige enlaces relativos erróneos (añade
/o usa rutas absolutas). Añade pruebas de enlace en CI y valida<base href>si aplica. - Time trap (calendarios): limita navegación a X meses (futuro/pasado), deshabilita “siguiente” al superar el límite, o devuelve
404/410para fechas inválidas. Si el calendario no debe posicionar, bloquea su rastreo. - Infinite redirect trap: revisa reglas y asegúrate de que cada URL tenga un destino único e idempotente (una sola cadena 301). Testea con un crawler antes de desplegar.
- Session URL trap: guarda sesiones en cookies (no en la URL). En PHP, por ejemplo:
session.use_trans_sid = 0 session.use_only_cookies = 1Elimina cualquier
?session=de los enlaces y purga el histórico si se indexó.
Configuración de robots.txt
Úsalo para restringir el rastreo de patrones problemáticos (no para solucionar la causa). Ejemplos típicos:
User-agent: *
# Facetas y ordenaciones
Disallow: /*?*sort=
Disallow: /*?*order=
Disallow: /*?*size=
Disallow: /*?*color=
# Sesiones y tracking
Disallow: /*?*session=
Disallow: /*?*utm_
# Buscador interno
Disallow: /buscar
# Calendario (si no debe rastrearse en absoluto)
# Disallow: /calendar/
Notas: robots.txt no elimina URLs del índice ya existentes, sólo desincentiva su rastreo futuro. Úsalo junto a canónicas/noindex o con respuestas 404/410 si procede.
Uso correcto de canonical tags
- En listados con filtros, apunta la canónica al listado base (p. ej.,
/categoria/). Esto consolida señales y evita duplicidad, pero no ahorra crawl budget por sí sola. - Evita canónicas en conflicto (no canonizar a URLs no equivalentes). Mantén coherencia con el enlazado interno y el sitemap.
- Si usas
<meta name="robots" content="noindex,follow">en combinaciones, compátalo con una canónica al listado base.
Control de parámetros en Google Search Console
Importante: Google retiró la herramienta de “Parámetros de URL”. Hoy, GSC se usa para monitorizar y diagnosticar, no para “decirle” a Google cómo tratar cada parámetro.
- Estadísticas de rastreo: detecta rutas/parámetros que consumen muchas solicitudes.
- Índice > Páginas: filtra por patrones para evaluar cobertura y problemas (soft 404, duplicados).
- Inspección de URL: comprueba canónica elegida por Google y presencia de directivas.
- Remociones: útil para ocultar temporalmente patrones sensibles mientras aplicas la corrección técnica.
- Sitemaps: incluye sólo URLs canónicas válidas y excluye combinaciones con parámetros.
Eliminación temporal de URLs por patrones desde Google Search Console
Otra solución complementaria, especialmente útil cuando un crawl trap ya ha generado muchas URLs indexadas o visibles en Google, es usar la herramienta de Eliminación de URLs en Google Search Console. Esta función no corrige la causa del problema, pero permite ocultar rápidamente las rutas afectadas mientras se implementa la solución técnica definitiva.
Cómo funciona: en la sección Índice > Eliminaciones puedes enviar solicitudes para ocultar temporalmente (aprox. 6 meses) un conjunto de URLs que sigan un mismo patrón o prefijo. Esto es útil para:
- Bloquear visibilidad de rutas con parámetros (
?session=,?sort=,?color=). - Evitar que calendarios (
/calendar/) o paginaciones infinitas aparezcan en resultados. - Reducir la exposición de combinaciones de filtros mientras se ajusta el enlazado y
robots.txt.

Importante: esta acción es temporal y no evita que Google vuelva a indexar las URLs si siguen siendo accesibles y rastreables. Debe combinarse siempre con la solución técnica (bloqueo en
robots.txt,noindex, redirecciones o eliminación del contenido).
Caso real: crawl trap por un plugin de calendario en WordPress
Cómo lo detectamos paso a paso
- Señales en GSC: picos en “Páginas rastreadas pero no indexadas” con rutas
/events/y/calendar/AAAA/MMmuy futuras. - Logs de servidor: patrones de Googlebot solicitando meses/años > 24 meses en el futuro (por ejemplo,
/calendar/2031/07). - Crawl con Screaming Frog: detección de enlaces “Siguiente mes” sin límite y crecimiento exponencial de URLs en la sección de eventos.
- Revisión del plugin: configuración por defecto permitía navegar indefinidamente a futuro, sin
noindexni cortes de navegación.
Solución implementada y resultados en el rastreo
- Límite funcional: tope de navegación a +12 meses y −12 meses desde la fecha actual; desactivación de enlaces “siguiente” fuera de rango.
- Respuestas correctas: para fechas inválidas, el servidor devuelve 410 Gone (o 404) en lugar de generar páginas vacías.
- Directivas: meta
noindex,followen listados mensuales; sólo la landing de eventos principal (/events/) permanece indexable y canónica. - robots.txt (si el calendario no es parte del SEO):
Disallow: /calendar/para evitar rastreo de archivos mensuales. - Sitemap: exclusión de URLs de calendario; sólo se incluyen eventos relevantes con valor orgánico.
- Verificación: nuevo crawl de control y seguimiento en “Estadísticas de rastreo” (GSC) y en logs para confirmar la caída de solicitudes irrelevantes.
Impacto observado (orientativo): reducción > 70% de solicitudes en /calendar/, mejor frescura en las secciones comerciales y caída significativa de “soft 404” en el informe de indexación.
¿Necesitas ayuda para optimizar tu rastreo web?
En Why Ads Media somos una consultora SEO especializada en mejorar la indexación y el rendimiento orgánico de todo tipo de sitios web. Si necesitas resolver problemas de rastreo, podemos ayudarte a diseñar una estrategia a medida para que buscadores y usuarios encuentren siempre tu contenido más relevante.
Contáctanos hoy y descubre cómo podemos mejorar la visibilidad y el SEO técnico de tu proyecto.