- #01 Tertulia | Captación clientes, CRM y Lead Scoring + Errores de marketing digital - marzo 23, 2026
- Meta campos de Shopify: qué son y cómo usarlos para que tu tienda venda más (SEO + UX + CRO) - febrero 13, 2026
- Guía de SEO en YouTube: cómo posicionar vídeos y convertir visitas en leads - febrero 10, 2026
En este artículo te vamos a explicar a fondo qué es este archivo y cómo puedes usarlo para mejorar tu visibilidad y posicionamiento SEO
¿Qué es el archivo robot.txt?
El archivo «robots.txt» es un componente esencial en la optimización SEO, que juega un papel fundamental en la gestión de la visibilidad de tu sitio web para los motores de búsqueda y otros rastreadores web.
Importancia del archivo robot.txt en SEO
El «robot.txt» desempeña un papel crucial en el SEO de tu página web, y te vamos a explicar el por qué:
Control sobre el rastreo
El archivo «robots.txt» te permite controlar qué partes de tu sitio web deben ser rastreadas por los motores de búsqueda y cuáles no.
Esto es esencial para evitar que los motores de búsqueda indexen contenido no deseado o privado, lo que puede afectar negativamente tu clasificación en los resultados de búsqueda.
Reducción de recursos
Al bloquear el acceso a ciertas páginas o archivos, puedes reducir la carga en tus servidores y mejorar la velocidad de carga de tu sitio web.
Esto no solo beneficia la experiencia del usuario, sino que también puede influir positivamente en tu posicionamiento en los resultados de búsqueda.
Evitar indexar contenido duplicado
Este archivo ayuda a prevenir problemas de contenido duplicado al evitar que los motores de búsqueda accedan a versiones duplicadas de tu sitio web
Mejora de la indexación
Al permitir que los motores de búsqueda accedan a las partes más relevantes de tu sitio y bloquear contenido no esencial, puedes asegurarte de que se indexe lo que realmente importa.
Reducción de errores de rastreo
Una configuración adecuada del archivo `robots.txt` puede prevenir errores de rastreo y notificaciones de problemas, lo que facilita la identificación y resolución de problemas técnicos.
Mayor control de SEO
La optimización del archivo `robots.txt` te da un mayor control sobre cómo los motores de búsqueda interpretan y clasifican tu sitio web, lo que puede ayudarte a mejorar tus clasificaciones y la visibilidad en línea.
Cómo funciona el fichero Robots.txt
El funcionamiento del fichero Robots.txt es sencillo, en un simple documento de texto plato alojado en la raíz de tu sitio web, se identifica quéo User-Agents que es como se identifican los Bots, qué URLs pueden o no pueden rastrear identificando con “Disallow” ó “Allow” la ruta concreta.
Ejemplo:
User-agent: *
Disallow: /privado/
Allow: /publico/
El archivo robots.txt debe estar ubicado en el directorio raíz de tu sitio web y lo puedes encontrar directamente estableciendo robots.txt en la url del dominio.
Ejemplo:
https://whyadsmedia.com/robots.txt.
Los motores de búsqueda y otrosweb lo buscan automáticamente en esta ubicación para obtener directrices sobre qué partes del sitio pueden o no pueden rastrear.
Elementos del archivo Robots.txt
A continuación, se describen los elementos clave que componen un archivo robot.txt:
- User-agent: Este es el primer elemento y define para qué motor de búsqueda o rastreador web se aplica la regla. Por ejemplo, puedes utilizar «User-agent: Googlebot» para dirigirte específicamente a Googlebot, el rastreador de Google. También puedes usar asteriscos (*) para aplicar una regla a todos los rastreadores. Por ejemplo, «User-agent: *» se aplicará a todos los motores de búsqueda.
- Disallow: Este elemento indica qué partes del sitio web no deben ser rastreadas por el motor de búsqueda especificado. Por ejemplo, «Disallow: /admin» evitará que el motor de búsqueda acceda a cualquier URL que comience con «/admin». También puedes usar un asterisco (*) para bloquear el acceso a todas las páginas, como «Disallow: /», aunque esto no se recomienda a menos que sea necesario.
- Allow: Aunque menos común, el elemento «Allow» se usa para permitir el acceso a ciertas partes del sitio web cuando se ha establecido una regla de bloqueo general. Por ejemplo, «Allow: /public» podría permitir el acceso a una carpeta específica dentro de un sitio bloqueado.
- Crawl-delay: Este elemento permite especificar un retraso en segundos entre las solicitudes sucesivas al servidor desde el mismo rastreador. Esto ayuda a controlar la carga del servidor y evitar que los rastreadores sobrecarguen el sitio web. Por ejemplo, «Crawl-delay: 10» establece un retraso de 10 segundos entre las solicitudes.
- Sitemap: Aunque no es parte del archivo robot.txt, es común incluir un enlace al archivo de mapa del sitio (sitemap) en el para ayudar a los motores de búsqueda a encontrar y rastrear todas las páginas importantes del sitio. Por ejemplo, «Sitemap: https://www.ejemplo.com/sitemap.xml» señala la ubicación del mapa del sitio.
- User-agent especial («User-agent: «): Si deseas aplicar una regla a todos los rastreadores, puedes utilizar «User-agent: *». Esto es útil cuando quieres establecer reglas generales que se aplican a todos los motores de búsqueda, como bloquear carpetas sensibles o evitar el acceso a ciertas partes del sitio web.
¿Cómo funcionan los comandos «Disallow» en un archivo robots.txt?
El comando “Disallow” Indica qué directorios o páginas no deben ser rastreados por los bots, algo crucial si tenemos en cuenta que podrías contener información sensible abierta a todo el público.
Ejemplo:
Disallow: /privado/ evita que losaccedan a la carpeta /privado/.
Si dispones de un sitio en wordpress, puedes revisar el fichero robots y verás que directamente se bloquea la carpeta de gestión con:
Disallow: /wp-admin/
Bloquear un archivo o una página web concreta
Si estás pensando en bloquear URLs o ficheros concretos, tan solo debes especificar la ruta completa del fichero/url.
Ejemplo:
User-agent: *
Disallow: /privado/bloqueado.html
Bloquear un directorio
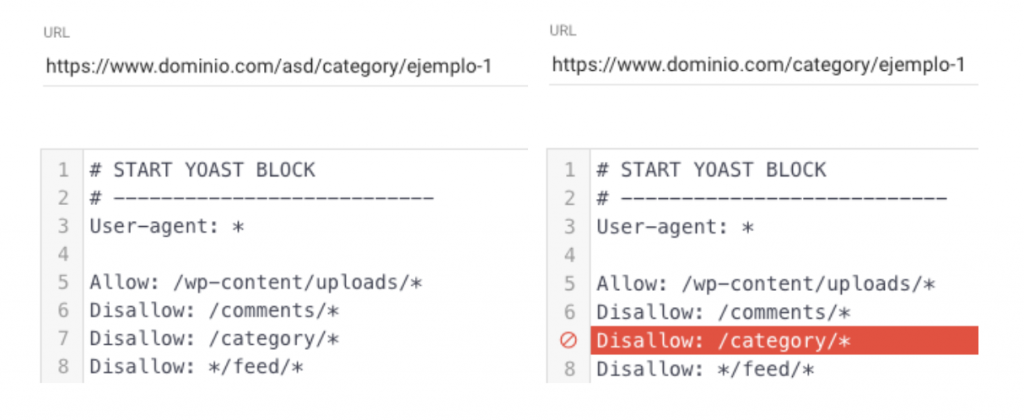
Para bloquear un directorio completo debes establecer el path que deseas bloquearten en cuenta que:
- Estableciendo la directiva Diasallow: /directorio/ solamente bloqueas lo precedido por el dominio.
dominio.com/directorio/ quedará bloqueado
dominio.com/prueba/directorio/ quedará habilitado - Si deseas bloquear un path concreto deberás utilizar el asterisco para evitar que no tenga en cuenta el contenido que tenga por delante o por detrás.
dominio.com/directorio/ quedará bloqueado
dominio.com/prueba/directorio/ quedará bloqueado
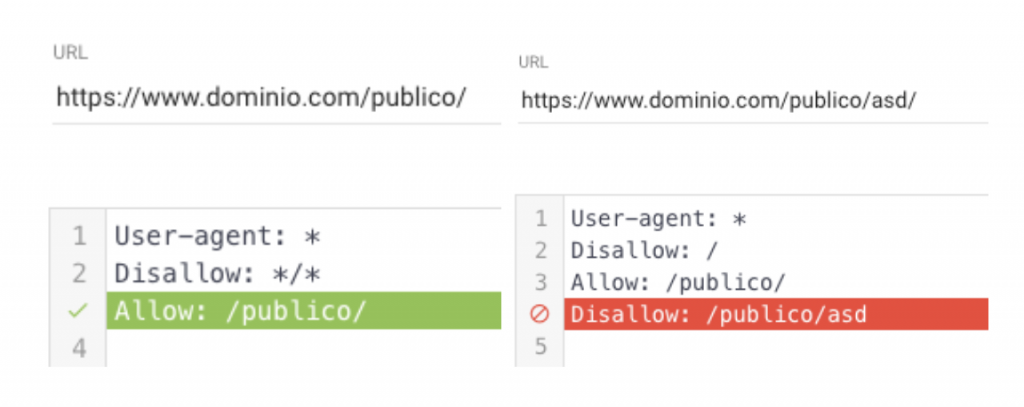
Permitir el acceso total
Para permitir el rastreo en zonas específicas, simplemente debes utilizar la directiva “Allow” de la misma manera que se utiliza “Disallow”, solo que en este caso deberás tener en cuenta que si se impide todo el rastreo del sitiose permite el rastreo de un path específico, lo tendrá en cuenta y podrá rastrear lo que considere.
Ocultar todo el sitio web a los bots
Cuando tenemos una página web en desarrollo y queremos que no sea rastreada por los buscadores, ya sea para evitar que pueda ser indexada o penalizada, se suele utilizar la directiva:
User-agent: *
Disallow: /
Este es uno de los fallos más comunes y puede provocar algún que otro dolor de cabeza al buscar el motivo por el cual no se indexa nuestra web una vez terminada.
Ocultar un sitio web a losde IA para que no usen tu contenido.
Teniendo en cuenta que con la directiva Disallow podemos impedir el rastreo de nuestro sitio y con User-agent especificar a quienes, podemos aprovechar para impedir que losde Chat GPT o similares puedan rastrear nuestro sitio.
Ojo con el orden, ya que si permitimos a todos losque puedan rastrear y luego especificamos una directiva que no lo permite, no lo tendrá en cuenta y podrás rastrear el sitio.
Ejemplo de cómo bloquear Chat GPT para evitar que no utilicen la información de tu web y Google Ads si no vas a realizar ningún tipo de campaña publicitaria.
Ejemplo:
User-agent: GPT-4
Disallow: /
User-agent: OpenAI-GPT
Disallow: /
User-agent: bingbot
Disallow: /
User-agent: AdsBot-Google
Disallow: /
Es de vital importancia probar cada una de las URLs cada vez que se implementen directivas Robots
Cómo generar un fichero Robots.txt optimizado
Ahora que ya sabes cómo gestionar el documento Robots.txt de tu sitio web, es hora de prepararlo para optimizar al máximo el presupuesto de rastreo o el “Crawl Budget” para hacer que los buscadores pierdan el mínimo tiempo posible rastreando tu sitio.
Aspectos a valorar para generar el fichero Robots.txt
Al crear un archivo robots.txt, hay varios aspectos importantes a considerar para asegurarte de que esté configurado de manera efectiva y cumpla con tus objetivos de SEO.
Determina el objetivo
- Control de Indexación: Decidir qué partes de tu sitio deben ser indexadas por los motores de búsqueda y cuáles no.
- Protección de Información Sensible: Evitar que losrastreen directorios y archivos que contienen información confidencial o sensible.
- Optimización del Crawl Budget: Asegurar que losde los motores de búsqueda utilicen su tiempo de rastreo en las páginas más importantes de tu sitio.
Identifica los User-agents
- Conocer los User-agents: Cada bot tiene un identificador único, como Googlebot para Google o bingbot para Bing. Es crucial identificar correctamente estos User-agents para aplicar las reglas adecuadas.
- User-agent Global: Utiliza User-agent: * para aplicar reglas a todos los bots.
Determina las ubicaciones
- Directorios y Archivos Clave: Identifica los directorios y archivos clave que deseas controlar, como /admin/, /privado/, /images/, etc.
- Ubicación de Archivos Sensibles: Asegúrate de proteger directorios y archivos que contienen información sensible o privada.
- Ubicación del Archivo Robots.txt: Coloca el archivo robots.txt en el directorio raíz de tu sitio web (por ejemplo, https://www.tusitio.com/robots.txt).
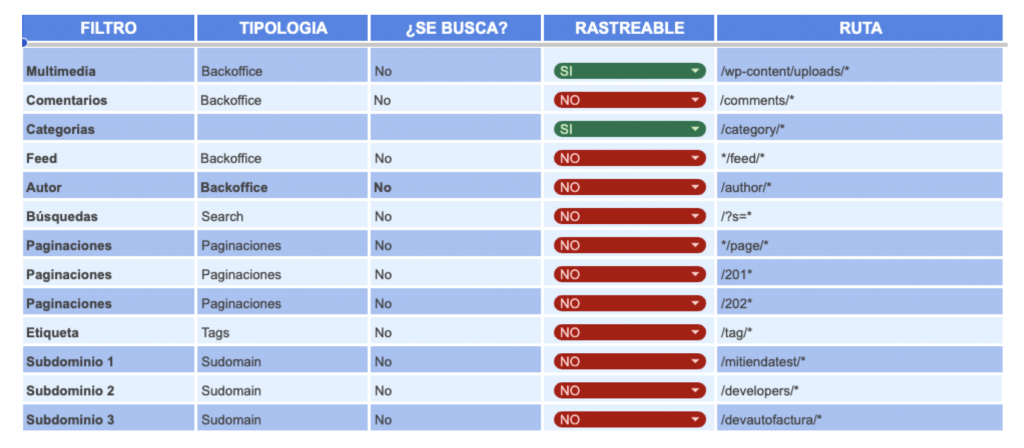
En Why Ads Media utilizamos una plantilla para determinar si queremos o no impedir el rastreo a los diferentes directorios de las páginas web para de esta manera, agilizar el proceso de creación.
Cómo probar el funcionamiento del fichero Robots.txt
Antes de subir el fichero Robots al entorno real, es necesario que le dediques unos minutos a probar que las reglas incluidas en él, funcionan correctamente.
En Why Ads Media te recomendamos el probador robots.txt de Technical SEO.
Deberás probar cada una de las variaciones disponibles en tu sitio.
Probar fichero Robots con Screaming Frog.
Probar tu archivo robots.txt con Screaming Frog es una manera de asegurarte de que está configurado correctamente y de que las reglas se aplican como esperas.
Solo deberás realizar los siguientes pasos:
- Realiza un rastreo del sitio actual respetando el fichero Robots y exporta los resultados a una hoja de cálculo.
- Crea el fichero Robots.txt.
- Súbelo a la web.
- Configura Screaming Frog para que tenga en cuenta el fichero Robots.
- Exporta los resultados a una hoja de cálculo
- Compara los resultados para ver qué URLs están siendo bloqueadas por Robots y cuáles no para determinar si se aplican o no los cambios sugeridos.